
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- javascript
- css
- JWT
- GraphQL
- 알고리즘
- Kubernetes
- 인접리스트
- bean
- dfs
- LifeCycle
- typescript
- Interceptor
- node.js
- html
- Linux
- 코딩테스트
- MySQL
- Deep Dive
- java
- 자료구조
- puppeteer
- TIL
- Spring
- OOP
- REST API
- winston
- 탐욕법
- nestjs
- 인접행렬
- 프로그래머스
Archives
- Today
- Total
처음부터 차근차근
[알고리즘] DFS 본문
728x90
깊이 우선 탐색(DFS)이란??
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법을 의미한다.
탐색하는 방법은 아래 그림과 같다.
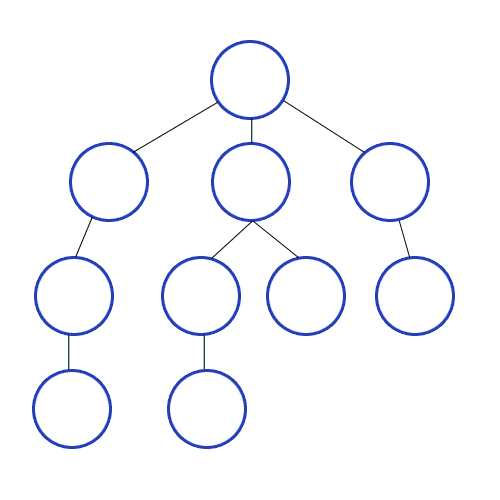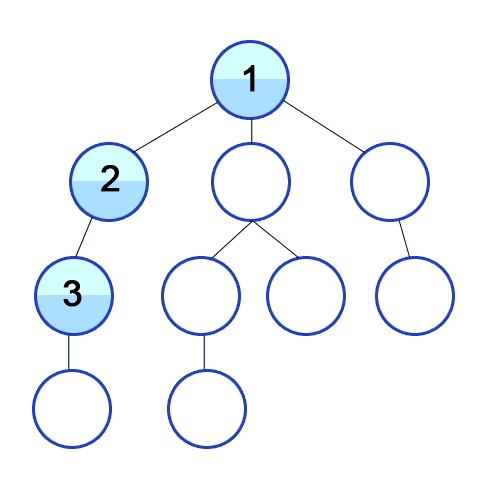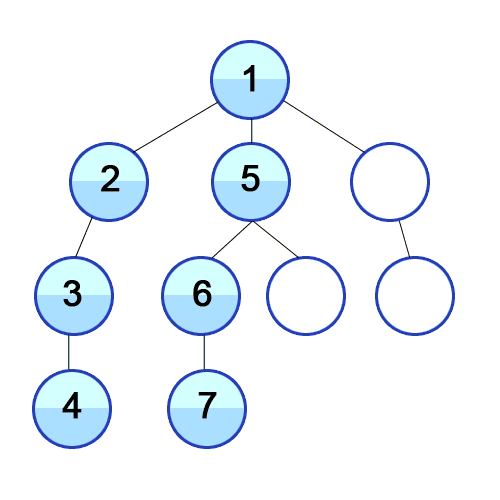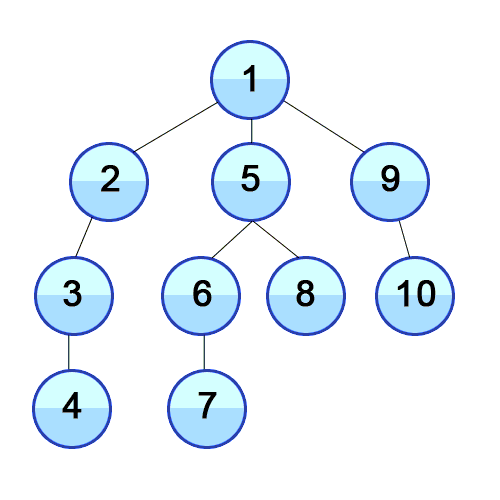
- 미로와 같이 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길로 돌아와서 이곳부터 다른 방향으로 다시 탐색을 진행하는 방법과 유사하다.
- 즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것을 의미한다.
DFS의 경우 모든 노드를 방문하고자 하는 경우에 이 방법을 선택한다.
깊이 우선 탐색의 특징
- 자기 자신을 호출하는 순환 알고리즘 형태를 가지고 있다.
- 전위 순회를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류이다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야 한다는 것이다.
- 이를 하지 않을 경우 무한루프에 걸린다.
DFS 구현 방법
구현 방법은 2가지가 있다.
- 재귀함수를 이용한 방법
- 스텍을 이용하는 방법
재귀함수를 이용하는 로직은 다음과 같다.
- 방문 여부를 기록하기 위해 visited라는 배열을 사용하며, 배열 visited의 값을 false로 초기화시킨다.
- 노드를 방문할 때마다 해당 노드의 visited 배열 값을 true로 한다.
- 해당 노드(v)와 연결된 노드 중에 방문하지 않은 노드(node)가 있다면 방문하지 않은 노드를 시작점으로 하여 DFS 함수를 다시 시작한다.
재귀함수를 이용한 코드는 다음과 같다.
// 재귀 함수를 이용한 DFS 구현
function dfs(graph, v, visited) {
//1. 탐색 시작 노드 방문 처리
visited[v] = true;
console.log(v);
// 2, 탐색 노드의 인접 노드를 확인
// v의 배열을 순회 진행
for (const cur of graph[v]) {
if (!visited[cur]) {
dfs(graph, cur, visited);
}
}
}
let graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7],
];
let visited = [...Array(9).fill(false)];
dfs(graph, 1, visited);
다음은 스택을 이용한 로직의 순서이다.
- 스택에 시작 노드를 push한다.
- 스택에서 노드를 pop하고 해당 노드(v)가 방문하지 않은 노드라면 방문처리 한다.
- 노드(v)와 연결된 노드 중에서 방문하지 않은 노드(node)가 있다면 stack에 push 한다.
- 스택의 길이가 0이 될 때 까지 2,3번을 반복한다.
스택을 이용한 코드는 다음과 같다.
function dfs(graph, start, visited) {
// 스택 생성
const stack = [];
// 스택에 초기값을 push 진행
stack.push(start);
while (stack.length) {
// 스택에 pop을 진행한다.
let v = stack.pop();
// 방문한 적이 없는 노드라면
if (!visited[v]) {
console.log(v);
// visited를 true로 변경
visited[v] = true;
// 반복문 진행하여 push 진행
for (let node of graph[v]) {
if (!visited[node]) {
stack.push(node);
}
}
}
}
}
const graph = [[1, 2, 4], [0, 5], [0, 5], [4], [0, 3], [1, 2]];
const visited = Array(7).fill(false);
dfs(graph, 0, visited);
// 0 4 3 2 5 1
DFS와 BFS의 차이점
- DFS가 BFS보다 좀 더 간단하다.
- 단순 검색 속도 자체는 BFS에 비해 DFS가 느리다.
DFS의 시간복잡도
DFS는 그래프의 모든 간선을 조회한다.
- 인접 리스트로 표현된 그래프 : O(V + E)
- 인접 행렬로 표현된 그래프 : O(V^2)
즉, 그래프 내에 적은 숫자의 간선만을 가지는 최소 그래프의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
참조
https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html
https://chamdom.blog/dfs-using-js/
'CS > 알고리즘' 카테고리의 다른 글
| [알고리즘] MergeSort (0) | 2024.01.02 |
|---|---|
| [알고리즘] Quick 정렬 (1) | 2024.01.02 |
| [알고리즘] 버블 정렬, 선택 정렬, 삽입 정렬 (0) | 2023.12.27 |
| [알고리즘] Backtracking, N-Queen 문제 (0) | 2023.11.16 |
| [알고리즘] BFS (1) | 2023.11.16 |
'CS/알고리즘' Related Articles
more



